We built 24 apps with AI. Three platforms. 561 vulnerabilities.
The experiment
Most of what's now being built on top of AI gets called vibe coding. Type what you want, hit enter, watch a working app appear thirty seconds later. Lovable, Replit, Manus, Bolt, V0, every team we know is using one of them or trying to. We've been using them at Kolega too, partly because they're genuinely useful and partly because we wanted to know what was actually in the output.
So we ran the experiment properly.
Eight app categories. Three platforms. Same brief on each platform, every time. Password manager. CRM. Property management. LMS. Healthcare clinic. Loan origination. Legal case management. HR. That's twenty-four codebases in total. We pushed every one to GitHub and pointed Kolega's scanner at it.
One thing we did differently to most "AI security" posts: we changed nothing. Default settings on every platform. Default templates. Default backends. No "make this secure," no "add input validation," no "review the auth flow." We did what a builder does when they sit down to ship something on a Tuesday afternoon. That's the only fair test, because it's the only test that matches what's actually shipping to production every day.
Here's what came back.
The matrix
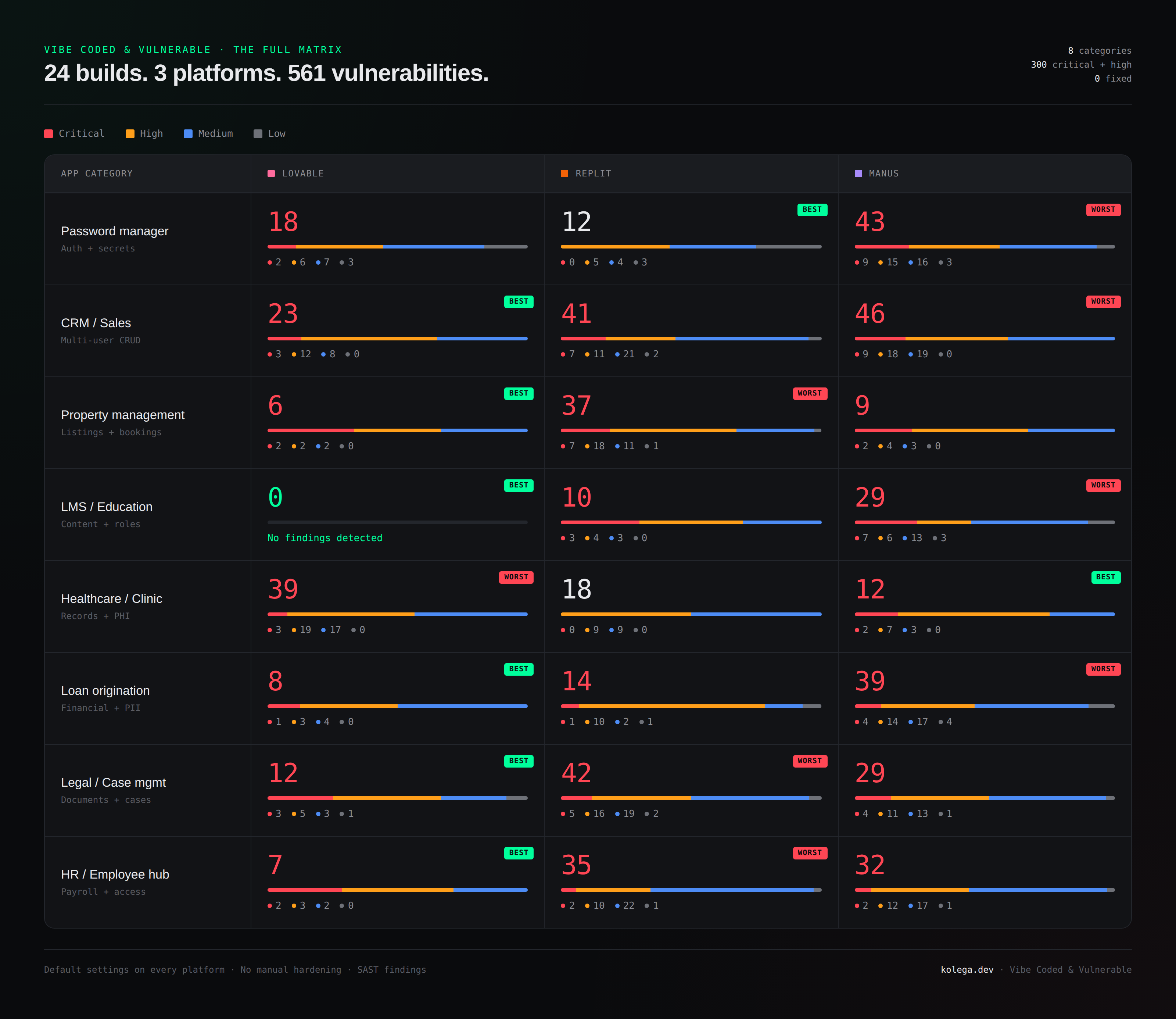
vcv-matrix
Every app we built. Every finding. Default settings on every platform, no manual hardening before scanning.
Five hundred and sixty-one vulnerabilities. Three hundred of them critical or high. Across twenty-four apps that, on every platform's own marketing site, were called "production-ready."
Zero of them came with fixes.
What the data actually says
Three things stand out, and the headline is the least interesting of them.
The headline is "AI builds insecure apps," which everyone already suspected. The quieter findings are the ones that change how you should think about this.
Almost nothing came back clean. Out of twenty-four builds, exactly one scanned with zero findings. A Lovable LMS. The other twenty-three shipped with somewhere between six and forty-six findings each. If the question is "will my vibe-coded app have vulnerabilities," the answer is "yes, with 96% certainty, based on this sample." Clean output from a generator is the exception. Not the rule. Not close to the rule.
Total findings hide the real story. Replit and Manus look similar on totals: 26.1 and 29.9 vulnerabilities per app on average. Lovable averages 14.1, which makes Lovable look like the clear winner. But on criticals, the ones that actually breach you, the gap widens differently. Lovable averages 2 criticals per app. Replit averages 3. Manus averages 5. Across eight builds each, that's sixteen, twenty-four, and forty critical vulnerabilities respectively. Two platforms that "look similar" ship 50% more breach-grade defects from one to the other. If you only look at totals, you'd never know.
No platform wins everything. Lovable wins six of eight categories outright. Replit takes the password manager (twelve findings, zero critical, against Manus's forty-three with nine critical on the same brief). Manus wins healthcare (twelve findings, against Lovable's thirty-nine on the same brief). The lazy version of this story is "use Lovable, avoid Manus." The honest version is that each platform has categories it's stronger at, categories it's catastrophic at, and you don't know which until you scan it. The same brief on the same day, generated by three different models, can produce a fifteen-finding app and a forty-five-finding app.
Why this happens, and it's not because the models are bad
It's tempting to look at 561 vulnerabilities and conclude that AI builders are dangerous, and you should go write your own code. That's the wrong lesson. The right lesson is that these tools were built with different goals than the ones we keep judging them by.
Default settings on every one of these platforms are optimised for "something working in front of the user." That means permissive CORS so the preview pane renders. Generous database access so the demo doesn't 500. Hardcoded API keys so the build doesn't require an env-var lecture before the user sees output. Every one of those defaults makes the "hit enter, watch it work" experience smooth. Every one of them is also a vulnerability when you ship it.
The training data doesn't help. The corpus these models learn from is overwhelmingly tutorials, Stack Overflow answers, and example code from documentation. Tutorials skip auth checks for clarity. Stack Overflow answers fix the specific bug being asked about and ignore everything else. Example code from documentation is built to show you the feature, not secure the feature. The training set is the world's largest collection of "this works in a tutorial" code, and that's exactly the code that comes out.
And none of the platforms we tested run a meaningful security pass before they hand you the output. Lovable has a Security Checker, which is one reason their numbers came back better. Replit and Manus don't, in any visible way. None of them have anything that reads data flow across handlers, which is the only way to catch the breach-grade bugs that actually matter.
So what you get is generators that ship working code with the security posture of a sample app. Which is fine if you're prototyping. Less fine if you're shipping the thing you're going to sell to customers.
We adopted new tools for writing code. We didn't adopt new tools for maintaining it.
This is the part that matters more than any single platform comparison.
The thing about vibe coding isn't that the code is bad. The code is fine. The code works. The code probably looks better than what most of us would have written, in the time we would have written it. The thing about vibe coding is that it shifts where the work goes. Less time typing. More time owning what you didn't type.
That shift has caught most teams flat-footed. The toolchain for writing code has changed completely in the last two years. The toolchain for maintaining code has barely budged. Most teams are still using the same scanners, the same review checklists, the same QA processes they used in 2022, applied to a codebase that's now sixty percent generated and growing.
It doesn't work. Old SAST tools were tuned for the bugs humans write. They flag the missing input check, the SQL injection, the unsafe deserialization, the SSRF. They don't flag the BOLA bug we wrote about last month, where the auth check is present but the query doesn't filter by the authenticated user. They don't flag the hardcoded Supabase key with full database access embedded in a frontend bundle. They don't flag the missing rate limit on the password reset endpoint that lets a researcher with a free account read everyone's source code. The bugs AI generates aren't the same shape as the bugs humans generate, and the tools designed to catch the latter aren't catching the former.
That mismatch has a name. We've used it before. We called it Control Drift: the space between what your team can ship and what your team can govern. Vibe coding makes that gap wider every week, and the tools most teams rely on aren't closing it.
The fix is the same one our last post pointed at, applied at a different layer. Read the data flow, not the syntax. Run that read on every PR, not once a quarter. Catch the bug at the place it's written, not the place a security researcher finds it after forty-eight days.
What you should actually do
Three things, in order.
Scan whatever you ship. Not your repo's main branch once a month. Every PR, every commit. The cost of catching a bug at the PR is roughly zero. The cost of catching it after a researcher posts a thread on X is whatever your company is worth.
Stop trusting platform defaults. If your stack inherits CORS settings, database permissions, or auth scopes from a generator's template, treat them as starting points and tighten them. The default exists because it makes the demo work. Your production isn't a demo.
Treat AI output the way you treat a junior dev's first PR. The code might be great. It also might have shipped a BOLA, a missing rate limit, and an exposed admin endpoint, and the model that wrote it has no idea which. Review the structure, not just the function.
Where this ends
We're in the build-fast era. That's not changing, and we're not asking it to. Building fast is solved. Twenty-four working apps in a week with three different platforms, that wouldn't have been possible at all in 2023. We built and tested all of them in under a month. The acceleration is real and useful and we're not giving it back.
Maintaining what you build at that pace, though, is where we still haven't caught up. The tooling hasn't shifted. The reviews haven't shifted. The mental model that "the model wrote it so it's probably fine" is doing a lot of quiet damage to a lot of codebases, and the bill comes due when somebody scans the repo and finds out what's in there.
That's Control Drift, again. And it's going to keep happening to AI-native teams until the industry stops pretending the scanner that worked in 2022 is going to catch the bugs that ship in 2026.
We built Kolega for the maintenance half of the problem. Not because nobody else can write a scanner, but because the scanners that exist were designed for a kind of code most of us don't really write anymore. The 561 vulnerabilities in this study didn't come from "AI is dangerous." They came from "we sped up the writing and forgot to upgrade the reviewing."
If you want to know what's actually in the AI-generated code you've shipped, scan it. We do that. It takes about three minutes.
kolega.dev — semantic analysis on every PR.