We Ran 15 Security Scanners Against Real Vulnerabilities. The Results Aren't Pretty
Let's get something out of the way first. One of the scanners in this benchmark is ours. Kolega.Dev is our product. It sits at the top of the leaderboard. We know how that looks. That's exactly why we open-sourced every single piece of this project. Ground truth labels. Scoring scripts. Raw output from every scanner. The interactive dashboard. If we got something wrong, you can prove it yourself. We want you to try.
So why did we do this?
Because the security scanning industry has a trust problem. Every vendor claims to be the best. They run their tools against OWASP's synthetic Java test cases (short artificial servlets that don't reflect how real apps work) and publish a blog post about how well they scored. Nobody shows you the raw data. Nobody lets you re-run the numbers. Nobody lines up their tool next to the competition on the exact same codebase.
We got tired of it. So we built the test ourselves.
What RealVuln actually is
We collected 26 Python repositories from GitHub. Flask apps, Django apps, FastAPI, aiohttp, Tornado. All intentionally vulnerable projects used for security education and CTF competitions. We went through every one of them by hand and labeled 796 findings. 676 of those are real vulnerabilities spanning 18 CWE families. The remaining 120 are traps. Code that looks sketchy on the surface but is actually safe. If a scanner flags one of those, it gets counted as a false positive.
Then we pointed 15 scanners at the same code.
The SAST side: Semgrep, Snyk Code, SonarQube. All running default configs.
The LLM side: Claude Haiku 4.5, Claude Sonnet 4.6, Claude Opus 4.6, Gemini 3.1 Pro, Grok 3, Grok 4.20 Reasoning, Kimi K2.5, GLM-5, Minimax M2.7, and Qwen 3.5 397B. All running in agentic mode with the same shared prompt. No per-model tuning.
The specialized side: Kolega.Dev (that's us) and GitHub's SecLab Taskflow Agent (which uses GPT-5.4 under the hood).
Every scanner ran against identical pinned commits. Same code. Same ground truth. Same scoring pipeline.
The leaderboard is live at realvuln.kolega.dev. Everything, the data, the code, the raw scanner outputs, is at github.com/kolega-ai/Real-Vuln-Benchmark.
How we scored it
Our primary metric is the F3 score. It weights recall nine times more than precision.
Why that weighting? Because a vulnerability your scanner misses can turn into an actual breach. A false positive costs someone 20 minutes of triage. Those two outcomes are not the same. In finance, healthcare, or critical infrastructure, the missed vulnerability is the one that matters. F3 captures that.
We report precision, recall, F2, and per-CWE breakdowns too. All the leaderboard data lives in the repo. You can re-rank under whatever weighting you prefer.
What we found
Three tiers. Not close. Not overlapping. Three clearly separated groups.
The SAST tier

The SAST Tier
Most engineering teams run one of these three tools. And on real code with real labels, they catch somewhere between 1 in 6 and 1 in 15 vulnerabilities.
Semgrep found 17.5% of what was there. Snyk got 16.7%. SonarQube was precise when it did flag something (61.1%), but it only flagged 6.5% of the actual issues.
Think about what that means for a second. If your SAST tool catches fewer than 1 in 5 real vulnerabilities, it's not actually protecting you. It's giving you a green checkmark. It's a rubber knife. Looks right. Feels right in your hand. Doesn't cut anything.
The LLM tier
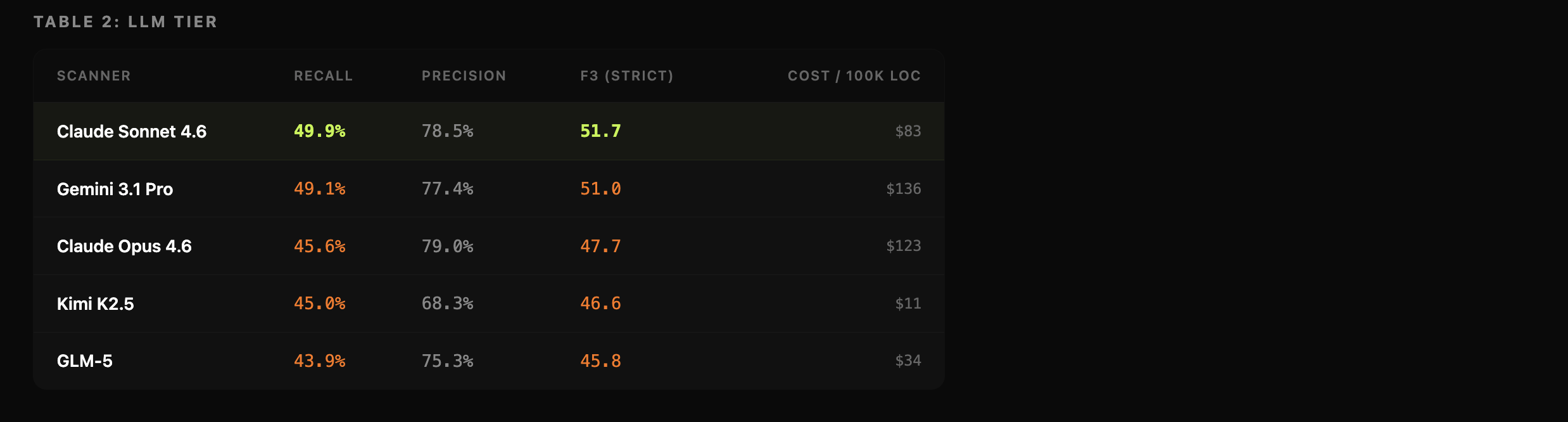
The LLM Tier
Sonnet 4.6 led the LLM pack with 49.9% recall. That's about three times better than any SAST tool we tested. But it still means half the vulnerabilities went undetected.
Two things surprised us here.
The bigger model didn't win. Opus 4.6 is Anthropic's most capable model. It also scored lower than Sonnet. The reason is boring but important: it timed out on 7 of 26 repos. Just never finished scanning them. Our strict scoring counts those as zero findings, because in production, a scan that never completes is a scan that never happened. If your tool can't reliably finish the job, the raw capability doesn't matter.
Spending more money doesn't help much either. Gemini 3.1 Pro runs $136 per 100K lines. Sonnet runs $83. Gemini scored 51.0, Sonnet scored 51.7. You're paying 64% more and getting marginally worse results. On the cheap end, Kimi K2.5 at $11 per 100K lines hit an F3 of 46.6. Not bad for a fraction of the price.
The specialized tier

The Specialized Tier
Kolega found 80.9% of vulnerabilities. F3 of 73.0. The next closest scanner overall was Sonnet at 51.7. A 21-point gap.
The precision tradeoff is real. Kolega's 38.8% precision is lower than the LLMs (most of which sit between 70% and 80%). But here's the thing: it's still higher than Semgrep at 20.5% and Snyk at 28.2%. So Kolega flags more stuff for review, yes. It also catches more of the stuff that actually matters. In a security context where one missed vuln can cost you a breach, that tradeoff makes sense.
GitHub's SecLab Taskflow Agent is a different animal. It runs a multi-stage threat-modeling pipeline on top of GPT-5.4. Impressive design. The problem is it picks only 3 to 5 threat categories per repository and does deep analysis on those. Precision is solid at 60.5%, but recall is just 7.7%. It finished below every SAST tool. Being purpose-built for security doesn't automatically mean you find more bugs. You also need to look broadly.
The blind spots nobody talks about
The per-CWE breakdown is where things get really interesting.
Scanners do fine on the classics. SQL injection sits at 76% average recall. Insecure deserialization: 77%. Command injection: 69%. These vulnerability types have had pattern-matching rules written for them for 15+ years. No surprise there.
Here's what scanners can't see:
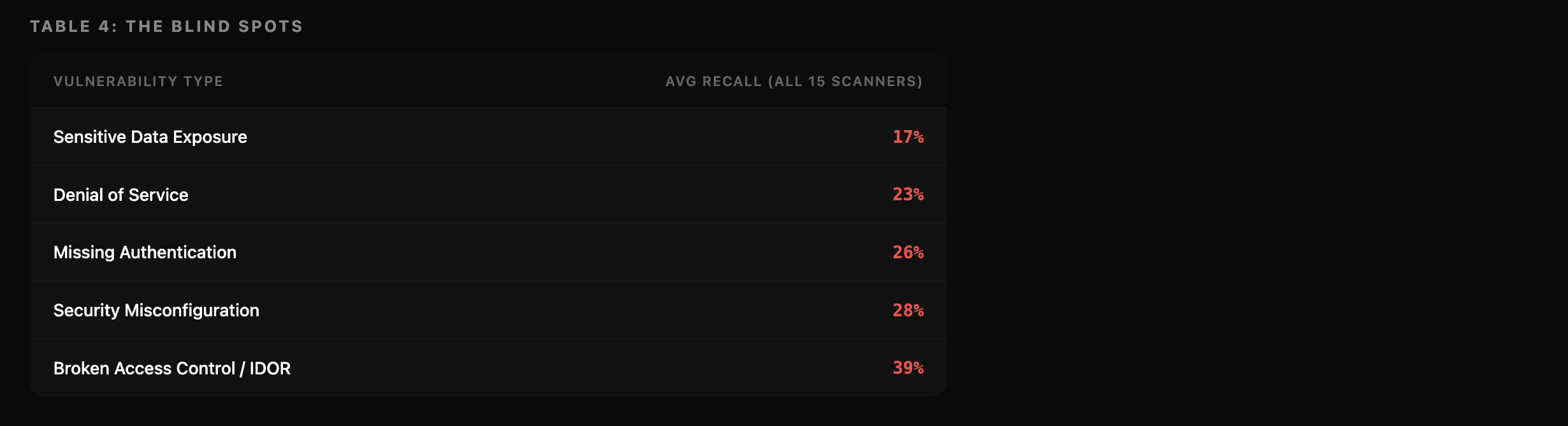
The Blind Spot
Sensitive data exposure sits at 17% recall. Flip that around: 83% chance your scanner walks right past it.
Missing authentication. 26%. This is the exact bug that keeps showing up in vibe-coded apps. The "anyone can call the API without a login" kind. Three out of four scanners don't catch it.
Broken access control. OWASP has ranked it number one for three years straight. 39% average recall across all 15 scanners.
The bugs scanners were originally built to find? They find those. The bugs that are actually causing breaches right now? Mostly invisible to every tool we tested. That green CI badge means your SQL injection rules passed. It says nothing about whether your app is actually secure.
Why the existing benchmarks miss this
OWASP Benchmark is synthetic Java. Tiny self-contained servlets where pattern matching works just fine. It never tests whether a scanner can trace an auth token across three files and notice the permission check is missing. So it never reveals where tools actually fail.
SastBench from Rival Labs (January 2026) gets closer. They assembled 2,737 samples from real CVEs. But the dataset is private. You can't download it. You can't re-run the scoring. You can't check their work. And they focused on triage agents, not raw detection accuracy.
ZeroPath, Cycode, DryRun, and Fluid Attacks have all published benchmarks of their own. Every one of them tests under conditions the vendor controls. Some share partial results. None of them give you the full package: open ground truth, open scoring code, open scanner outputs, false-positive measurement, and head-to-head comparison across all three scanner categories.
We compared RealVuln against every other benchmark we could find across seven properties. It's the only one that covers all of them. The full comparison table is in the repo.
Where RealVuln falls short
We're going to be upfront about what this version doesn't cover.
It's Python only. Flask, Django, FastAPI, aiohttp, Tornado. We have no data on TypeScript, Go, Java, or anything with manual memory management. Adding JavaScript/TypeScript, Go, and Java is the first priority for v2.
Every repo in this dataset was built to be vulnerable on purpose. Educational projects and CTF challenges, packed with bugs by design. Real production code has far fewer vulnerabilities per line. Scanner performance could look different at lower density. V2 will add real production applications with CVE-linked commits and normal bug rates.
LLM contamination is a real concern. All 26 repos are public on GitHub. Some of the LLM scanners we tested probably saw this code during training. If a model memorized the vulnerabilities, its recall numbers could be artificially high. Our 120 false-positive traps provide a partial check (knowing a file has bugs doesn't help you avoid flagging safe code in that same file), but it's not a complete solution. V2 will include repos published after model training cutoffs.
We only have two specialized scanners in the mix. We reached out to several other vendors. Some didn't respond. Some said no. If you build a security scanner and want to be included, the contribution guide has everything you need. We genuinely want more entries.
And yes. We created this benchmark, and our tool scores the highest. That's a legitimate concern. We've published everything so you can audit the labels, re-run the scoring, and call us out where we're wrong. Transparency is the best we can do here.
What to do with this data
Running SAST and nothing else? The data says you're catching less than 1 in 5 real vulnerabilities. Layering in an LLM-based scanner or a purpose-built tool roughly triples your detection. That's not opinion, that's what we measured.
Shopping for an LLM scanner? Sonnet 4.6 and Gemini 3.1 Pro lead the pack. But watch the completion rates. Opus is technically the stronger model, and it scored lower because it kept timing out.
Build security scanners for a living? Send us your results. The contribution guide is in the README. If your tool outperforms ours, it goes to the top. No tricks.
Want to poke holes in our work? Please do. We labeled 796 findings by hand. Some of those calls are definitely wrong. Open a GitHub issue, show us the evidence, and every valid correction gets credited in the changelog.
This thing is meant to grow
New scanner submission? Leaderboard updates. New repo? Coverage expands. Corrected label? Ground truth gets better. The dashboard at realvuln.kolega.dev rebuilds on every merge. Previous versions stay intact because each release is locked to a manifest hash covering the ground truth, the repo commits, and the prompt versions.
V2 roadmap: JavaScript/TypeScript, Go, and Java repos. Production code with real CVEs at normal vulnerability density. A Docker-based sandbox for reproducible LLM evaluation. Community-submitted repositories.
Want to add a repo, submit scanner results, or challenge a label? The process is in the repository README.
Verify it yourself
Every number in this post is reproducible. Ground truth is open. Scoring code is open. Raw output from all 15 scanners is open. Dashboard is open.
Run it: github.com/kolega-ai/Real-Vuln-Benchmark
Leaderboard: realvuln.kolega.dev
We built this because nobody else had, and honestly, because we needed to know if our own scanner actually worked. Turns out it does. But don't take our word for it. That's the whole point.