We Needed a Benchmark That Didn't Exist. So We Built One.
There's a question nobody in security tooling answers cleanly: how do you know your tool would actually catch real-world vulnerabilities?
We ran into this early building Kolega.dev. We were doing something different from traditional SAST, and we needed to measure whether it was working - not in the sense of returning output, but actually finding the class of vulnerability that pattern-matching tools miss. Without a way to measure that, you are guessing.
The result is RealVuln Benchmark — open source at github.com/kolega-ai/Real-Vuln-Benchmark, with live results at realvuln.kolega.dev. The rest of this post explains how we built it and what we learned.
So we looked at what existed.
OWASP, Juliet, NIST SARD - the most established names in the space. But it's common knowledge among practitioners that scoring well on these doesn't translate reliably to catching real-world vulnerabilities. They were built to evaluate rule-based scanners: does the tool flag eval(user_input)? Does it catch obvious SQL concatenation? That's a narrow slice of the problem.
The thing is, these benchmarks were never designed to cover semantic analysis. They test one dimension of a much bigger problem space, and running a tool that does something different against them produces results that look fine but tell you nothing. We needed something new, and since it didn't exist we had to build it.
What we were actually trying to find
The gap between pattern-matching and semantic analysis sounds abstract until you look at specific examples. Let me walk through the four categories that kept coming up, because this is where the benchmark had to actually be different.
The first is cross-file data flow. Most SAST tools analyze each file independently. That means a vulnerability where user input enters the system in one file, gets partially handled in another, and reaches a dangerous sink in a third is essentially invisible to them. Each individual file looks fine. The flaw only exists in the path connecting them.
We found this pattern repeatedly. A SQL injection where the user-controlled parameter came in through a route handler, passed through a helper function that looked like it sanitized things but didn't cover all cases, and ended up in a database query three files away. Semgrep saw the query and the helper and flagged nothing because from its perspective each piece looked clean. You need to trace the full path to see the problem.
The second category is logic errors in authorization. This is the one that genuinely surprised me when we started seeing how often it appeared. The code has authorization checks. They just don't work. Not because they're absent, but because of small mistakes in the logic that are almost impossible to catch by reading the code quickly.
Here's a real example from a production secret management tool we analyzed. The authorization check was:
Read that quickly and it looks like it's checking whether the user exists before running the permission check. Reasonable. But Python's operator precedence parses not user_id is not None as (not user_id) is (not None). When user_id has a value, that expression evaluates to False is True, which is False. So the condition is never true. The permission check never runs. Ever.
What made this worse was finding nine separate authorization bypasses in that same codebase all tracing back to variations of the same class of mistake. Type confusion where a User object gets passed where a user_id string is expected. Authorization functions called with the wrong arguments silently returning the wrong result. Exception handlers that catch auth failures and convert them into user not found errors, accidentally making auth bypass look like a missing account.
None of these have dangerous syntax. There's nothing to pattern-match against. A scanner looking for known-bad code patterns will read through all of it and report clean. Finding this stuff requires understanding what the code is supposed to do and comparing that against what it actually does.
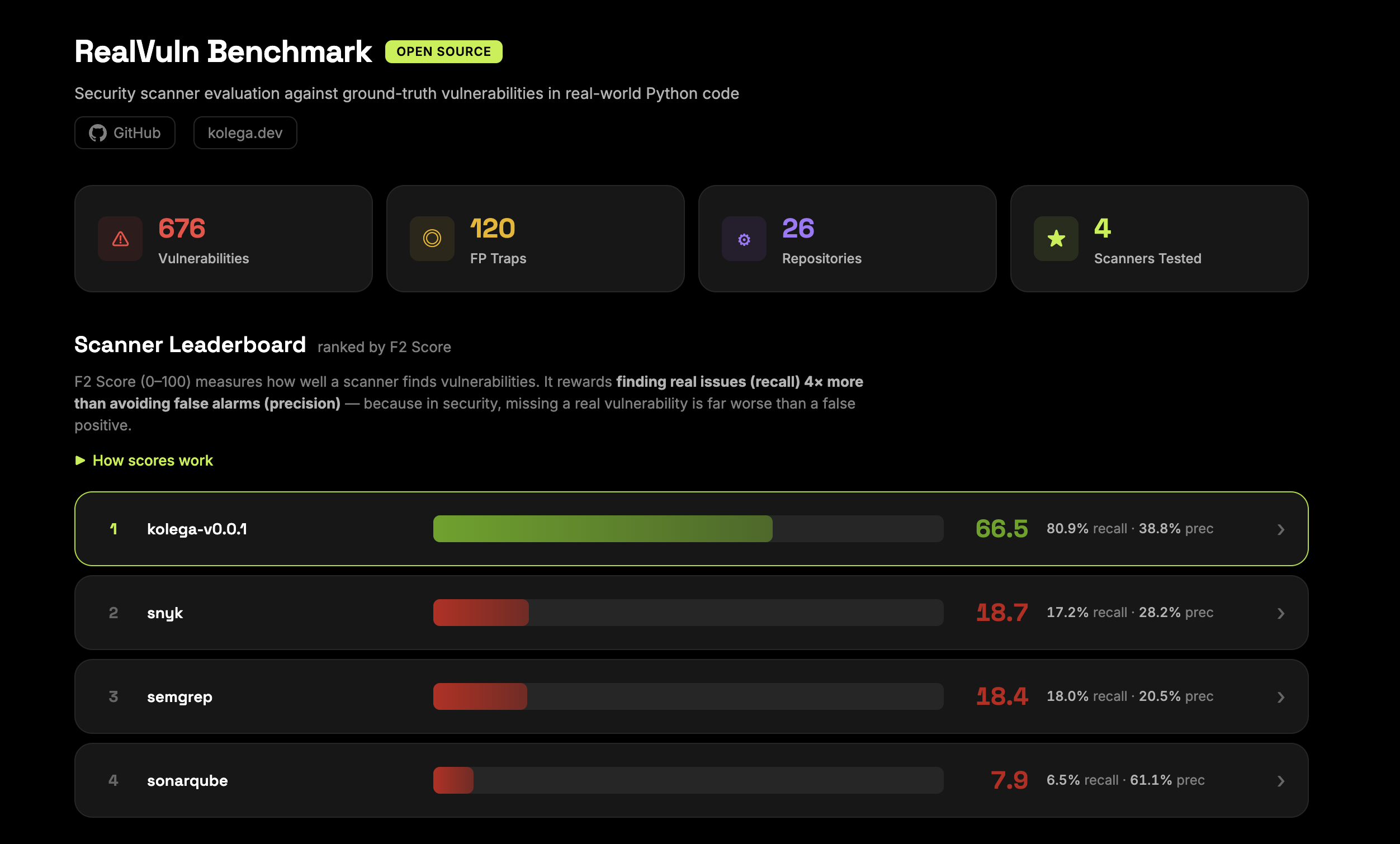
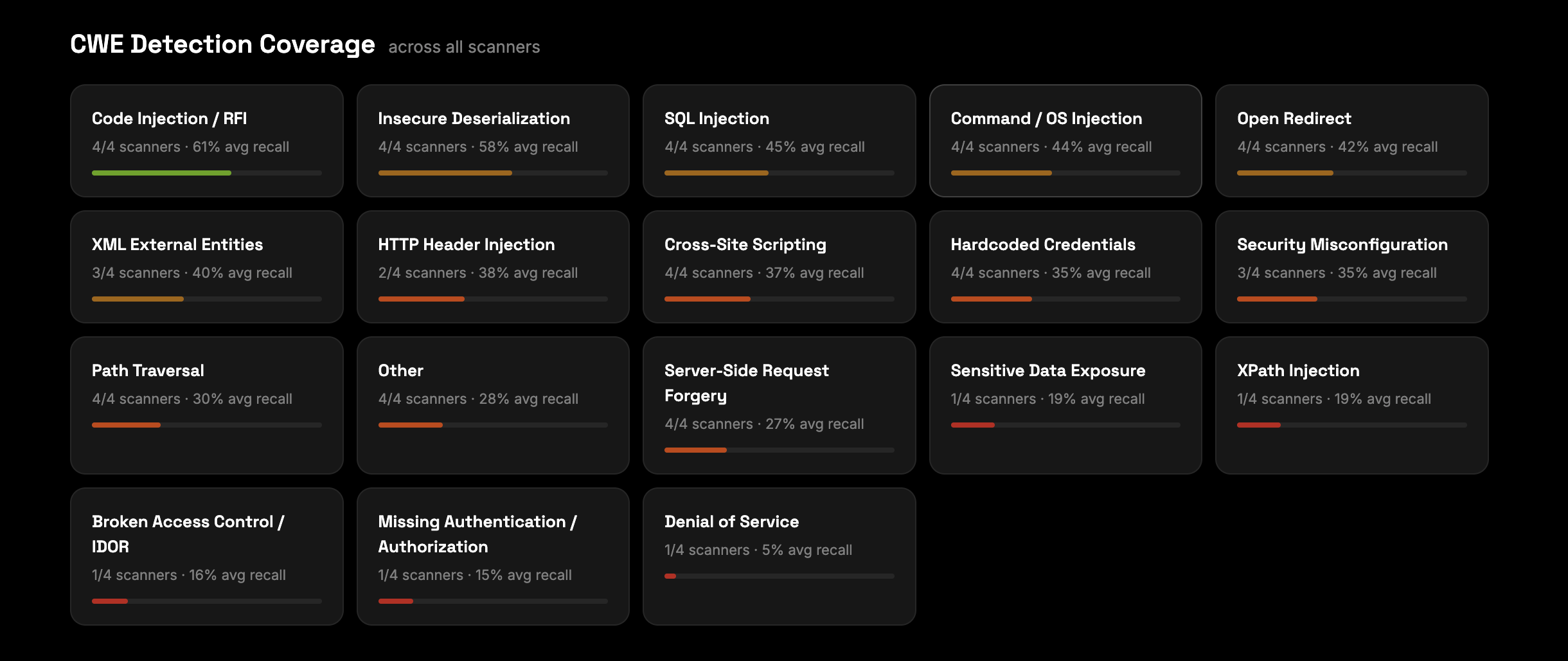
The dashboard at realvuln.kolega.dev shows this pattern clearly in the CWE detection coverage data. Across all four scanners we've tested, broken access control and IDOR sits at 16% average recall. Missing authentication and authorization is at 15%. These are the hardest classes to find - not because they're rare, but because they don't look like patterns.
The third category is race conditions in async code. Take this:
The logic is correct for a single request. Check whether something has already been approved, raise an error if so, create the approval inside a transaction. Looks fine. But the check and the write are not atomic. Two concurrent requests can both pass the check before either one has committed its write. Both proceed. Both create approvals. The duplicate check that was supposed to prevent this never fires for either of them.
This kind of bug works perfectly in testing because tests typically run single-threaded. It breaks under real load. Finding it requires modeling what happens when multiple execution paths run simultaneously, which is a fundamentally different kind of analysis than reading what a single request does.
The fourth category is framework lifecycle misuse. This one is subtle because the security code exists and looks correct when you read it. We found this pattern in multiple projects:
onResponse runs after the request has already been handled and the response has been sent. The auth check is there. It just runs too late to do anything. A scanner that searches for verifyAuth and confirms it's present on the route would mark this as protected. The framework executes the handler, sends the response, then runs the auth check against a completed request. Understanding why this is wrong requires knowing how the specific framework's request lifecycle works, which hook runs when, and what too late actually means in this execution model.
Building test cases that actually test this
The hard part of building a benchmark isn't writing the scoring engine. It's creating test cases where you genuinely know the right answer.
For launch, we built on intentionally vulnerable apps - projects specifically created to demonstrate security flaws, like DVWA, PyGoat, and Vulpy. These are synthetic in that they exist to be broken, but they're well-documented, widely used in security training, and give us verified ground truth: we know exactly what's there and where.
This approach has a real advantage: every vulnerability is confirmed and mapped. There's no ambiguity about whether something is a false positive or a real issue. The tradeoff is that intentionally vulnerable apps are cleaner than production code. The vulnerabilities are meant to be found. That's useful for establishing a baseline, but it's not the full picture.
The next phase is real open-source repositories - production code with disclosed CVEs, pinned to the commit before the patch. That's harder to build ground truth for, but it's where the benchmark becomes genuinely predictive of real-world performance. It's in the roadmap.
For each test case, the structure is the same regardless of source: a code sample with a known vulnerability, a patched variant that should not be flagged, and verified expected outcomes for both. Either the tool finds the real one and ignores the patched one, or it doesn't.
We also added false positive traps throughout - code that looks suspicious but is actually safe. A query builder that appears to concatenate user input but actually parameterizes correctly. A JWT decode call that looks like it skips verification but uses a properly configured library. A tool that flags everything scores well on recall while being useless in practice. Both dimensions matter.
What the results actually show
The benchmark is live at realvuln.kolega.dev with results across four scanners: Kolega, Semgrep, Snyk, and SonarQube, tested against 676 ground-truth vulnerabilities across 26 repositories with 120 false positive traps built in.
RealVuln Benchmark
The primary metric is F2 score, which weights recall four times more than precision. In security, missing a real vulnerability is considerably worse than a false alarm, so the scoring reflects that. The leaderboard currently shows Kolega at 66.5, Snyk at 18.7, Semgrep at 18.4, and SonarQube at 7.9.
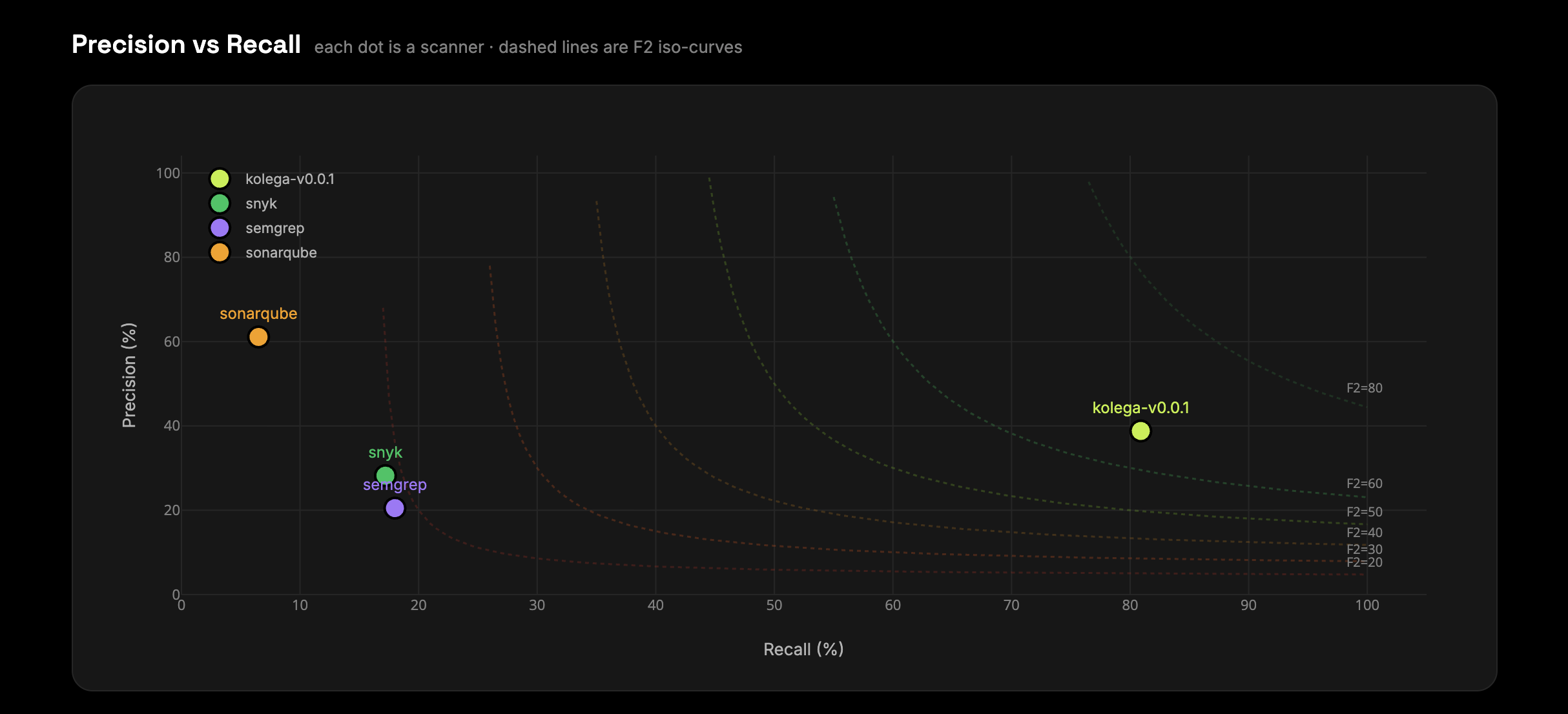
The precision-versus-recall scatter plot tells the more interesting story. SonarQube sits top-left: 61% precision, 6.5% recall. High confidence in what it flags, but it misses the overwhelming majority of real vulnerabilities. Snyk and Semgrep cluster in the middle - 17 to 18% recall, 20 to 28% precision. Kolega sits far right at 80.9% recall, 38.8% precision.
Graph
The tradeoff is real. Higher recall comes with lower precision - there are more findings to review. But a scanner that finds 6.5% of vulnerabilities while being highly confident about that 6.5% is not a useful security tool. The F2 weighting exists precisely because the cost of a missed vulnerability is not symmetric with the cost of a false alarm.
The CWE breakdown is where it gets specific. Code injection and insecure deserialization are at 61% and 58% average recall across scanners - these are pattern-detectable. SQL injection is at 45%. But broken access control and IDOR is at 16%. Missing authentication and authorization is at 15%. Denial of service is at 5%. The classes that require semantic understanding of what the code is supposed to do are exactly where the gap between tools is widest.
CVE
The per-repository heatmap shows how this plays out across individual targets - which repos each scanner struggles with, and where different tools have complementary blind spots. It's all on the dashboard.
The model comparison we didn't plan to do
Once we had a benchmark with known outcomes, the obvious next thing was to start running different language models through it. This wasn't the original plan. It was a side project that used infrastructure we'd already built. The results were genuinely not what we expected.
The model with the highest recall on our benchmark wasn't the most capable frontier model. It was a model with different training characteristics that turned out to be unusually sensitive to this class of semantic vulnerability. In practice it was surfacing around 80 to 90 percent of known true positives, more than anything else we tested.
The catch was noise. The same sensitivity that made it good at finding real vulnerabilities also made it flag a lot of things that weren't vulnerabilities. You might get 500 findings from this model where 400 of them need to be filtered out before the output is usable.
The frontier models flipped this profile. Better precision, cleaner output, but they missed a higher percentage of the true positives. Neither was strictly better. You're trading recall for precision depending on which model you use.
Without the benchmark this tradeoff is invisible. You can watch total finding counts change as you switch models, but you have no idea whether that's more real vulnerabilities being found or more noise being generated. The benchmark separates them. It turns a vague sense that this model seems noisier into actual numbers you can act on.
Once you can see the curve clearly, the obvious question is whether you have to pick a single point on it. That's an active area of exploration for us, and it's one of the things the benchmark makes it possible to test empirically rather than just reason about.
None of this was something we planned to build. It came directly from having measurement infrastructure that let us see what was actually happening.
The Python observation
One thing that came up repeatedly in the model testing that I think is worth noting: language matters more than most people assume, and not in a uniform way.
Python is harder than it looks. It's dynamically typed, which means a lot of security-relevant behavior - what type an argument actually is, what a function call resolves to, what a conditional actually evaluates - cannot be determined by reading the syntax alone. The logic error examples above are all Python. That's not a coincidence. The double-negative authorization bypass works because Python's operator precedence does something non-obvious. The type confusion vulnerabilities work because Python will happily accept a User object where you intended a user_id string and the function will silently behave differently than expected.
Most models have seen a lot of Python code during training, which you might expect to help. But there's a difference between having seen lots of Python and having learned Python security reasoning well. A lot of that training data reflects patterns that happen to work in the common case. The edge cases where Python's dynamic typing creates security issues are underrepresented. Models that score well on Python security tasks in our benchmark have genuinely learned something about how Python behaves under adversarial conditions, not just how Python looks.
TypeScript and Java are different. Static typing eliminates some whole classes of vulnerability structurally. The interesting problems shift toward architectural issues, logic errors in access control flows, and the kind of cross-boundary data flow problems that require understanding the whole application rather than individual files. Models generally have better-calibrated confidence in statically typed languages because the type information constrains what's possible. We're still working through what this means for benchmark coverage.
Why open source
A benchmark held internally measures one tool against one team's test cases. Held in common it can measure the whole field.
The practical reason is that our test cases will be wrong in places, and more people running things against them is the fastest way to find out where. We've already caught errors ourselves. Outside review will find more.
The research reason is that the questions the benchmark enables are genuinely interesting and we can't answer them alone. The authorship question in the roadmap is a good example. As codebases shift toward having more LLM-generated code, do scanners trained on or using LLMs perform measurably better on that code than on human-written code? Nobody has data on this. It's a real question with real implications for how security teams should think about tooling choices as their codebases change. Answering it requires running a lot of different tools against matched test cases with known authorship, which requires a lot of people contributing results.
The benchmark is currently 26 Python repos, 676 vulnerabilities, 120 false positive traps, 4 scanners on the leaderboard. JavaScript, TypeScript, Go, and Java are on the roadmap.
The live results dashboard is at realvuln.kolega.dev. The benchmark repository is at github.com/kolega-ai/Real-Vuln-Benchmark.
If something is wrong, open an issue. If a vulnerability class is missing, open a PR. If you run a scanner or model against it and get results worth sharing, add them. We'd like to know what you find.